
New – CRISPR and other New Resources
We have curated various arrayed CRISPR resources such as Cas9 constructs which we keep in bacterial and lentiviral format in stock to generate cell lines on demand. We are also actively building a repository of Cas9 carrying cell lines which are clonal and have been characterized in detail. These are available for use in projects using our screening services only. We have also various other reagents such as overexpression systems that allow for the delivery of larger cDNA’s without the need for viral packaging but still yield stable cell lines. For most of our reagents, we have constitutive as well as inducible formats are available for your use. The build-out of targeted libraries for resource is ongoing and we would love to incorporate your feedback!
Human Genome Wide Arrayed CRISPR Library
We are pleased to offer access to a full genome wide arrayed CRISPR library covering the human genome with 65,000 clones, i.e. each gene will have on average 3 constructs, i.e. 6 guides available. Our library is unique in that it contains two guides per plasmid. Individual clones for your targets and subsets are also available for screening.
We also have several human and mouse genome wide collection pooled CRISPR libraries available for screening. These are particularly useful for phenotypes where a complete gene knockout rather than a modulation of the gene can be couples with lethality or reporter gene assays.
Importantly: All of our libraries are available as individual clones – i.e. we can provide you CRISPR guides, shRNA’s or cDNA’s within a matter of days at a fraction of the cost of an outside vendor. We also offer cell line generation services drawing on our expertise in CRISPR KO, CRISPR-i, CRISPR-a and cDNA genome engineering strategies.
Small Molecule Libraries
Our compounds libraries are split into 4 segments: Pharmacological validation and repurposing libraries (LOPAC, Prestwick and Microsource spectrum, 2750 clinical kinase inhibitors annotated with targets, ~1k epigenetic modifiers ), targeted libraries for high value protein classes, covalent modifiers, lead-like libraries, and diverse libraries and diverse/smart libraries. All of our compounds are at least 90% pure. On average, we can resupply 90%-95% of the hit compounds as powder for follow up. With the exception of the diverse library (UCLA set) which is a pre-plated set, all of our sets are custom sets and are not likely to be found in another screening facility. We have applied extensive filtering against liabilities such as reactive groups, aggregators etc. The drug-likeness and usefulness of our pharmacological validation and re-purposing libraries as well as our custom libraries is well established. We found a historic sucess rate of about 90-95% in delivering tractable hits from our libraries across all targets.
FDA Approved Drug Library
A unique collection of 1,536 high-purity chemical compounds (all off patent) carefully selected for:
- Structural diversity
- Broad spectrum covering several therapeutic areas (from neuropsychiatry to cardiology, immunology, anti-inflammatory, analgesia and more)
- Known safety and bio-availability in humans
LOPAC Collection
Collection of 1,280 pharmacologically-active drug-like molecules for use in the fields of cell signaling & neuroscience. It covers the following target classes and is extremely useful for assay validation:
- Apoptosis
- G Proteins & Cyclic Nucleotides
- Gene Regulation & Expression
- Ion Channels
- Lipid Signaling
- Multi-Drug Resistance
- Neurotransmission
- Phosphorylation
Microsource Spectrum Collection
2000 biologically active and structurally diverse compounds from our libraries of known drugs, experimental bioactives, and pure natural products.
Epigenetic Modifier Library
The library contains epigenetics-related compounds targeting HDAC, Histone Demethylase, Histone Acetyltransferase (HAT), DNA Methyltransferase (DNMT), RNA read/write modifiers, Epigenetic Reader Domain, MicroRNA, etc.
Cysteine Reactive Library (Covalent Inhibitor Library)
3500 drug-like (they are rule of 5 or better) compounds with warheads against cysteines. This library contains a diverse selection of different warheads with specific properties tuned to ensure enough reactivity towards cysteine targets while also maintaining specificity.
Kinase Inhibitor Library
This set includes 2,750 annotated kinase inhibitors covering about more than 1/3rd of the kinome enabling pathway dissection.
GPCR library
This set contains 2290 GPCR modulators that are annotated with targets that cover classes 5-HT Receptor, Dopamine Receptor, Opioid Receptor, Adrenergic Receptors, Cannabinoid Receptor, mGluR, ETA Receptor, etc.
Non-annotated Compound Properties
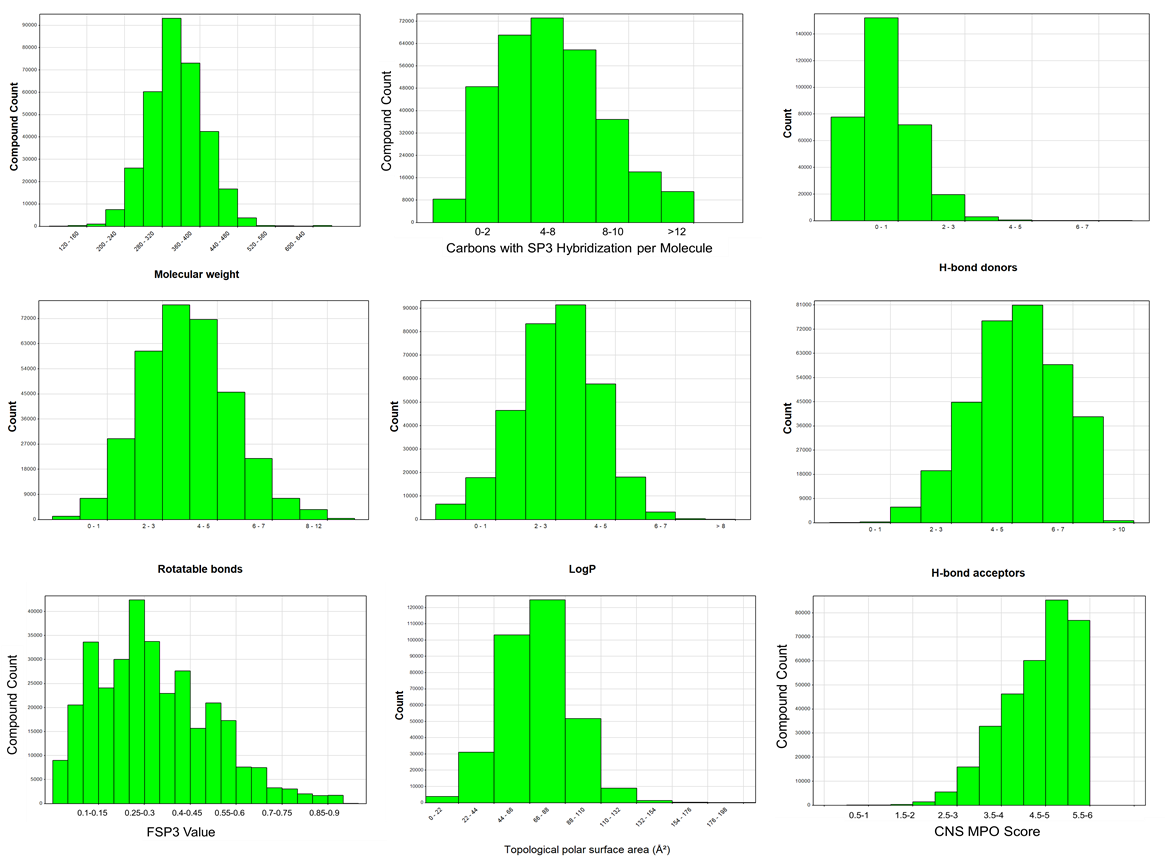
Overview of the molecular properties of the smart library space – 300k compounds are available at the MSSR. As of note, the compounds are Lipinski rule of five compliant, with many of them being compliant with the rule of 4 which is a stricter rule set frequently employed in pharmaceutical companies to ensure optimizability during hit-to-lead campaigns. Of particular note is that our compound sets are heavily enriched in SP3 content and also blood brain barrier penetrant, which was design feature during compound selection. We have curated our compound libraries specifically with 3D-dimensionality in mind in order to have the best change of finding compounds that can bind into a multitude of targets. Moreover, most of our compounds have a CNS MPO score >4, which makes them also suitable for CNS drug discovery projects and decreases the likelihood of being a drug efflux pump substrate which is extremely important for novel cancer therapeutics. Through historical data analysis, we have seen that our compound deck provides tractable chemical matter in ~90% of our projects.
Druggable Compound Set
A set of about 8000 compounds which are targeted at kinases, protease, ion channels and GPCR’s. These compounds are designed to match our siRNA efforts which are based on sets of siRNA’s for the druggable human and mouse genome. This set of 8k compounds was subjected to high-throughput docking to kinases,proteases, ion channels and GPCR’s and included in this set based on their predicted ability to bind to these high-value targets. The drug-likeness of this set is excellent, compounds from this set obey the rule of 5 – many of them even the rule of 4.
Lead Like Compound Set
This set of 20,000 compounds has been custom tailored for us for lead likeness. The compounds in this set are not to be found in any of the traditional “Russian” collections. The lead-like library obeys the more stringent rule of 4 rather than the more permissive rule of 5. This library was selected from a set of about 250,000 compounds to yield compounds which have more favorable properties for subsequent medchem optimization as the average molecule from this set is smaller, has fewer h-acceptor or donor sites and a better logP. It addresses the typical problem that during chemical optimization the compounds typically get heavier and less drug-like leading to more potential for ADME-problems in subsequent stages.
Chemically Diverse Libraries (CombiChem and Traditional Liquid Phase Medicinal Chemistry Libraries)
ChemBridge DiverSet, 30,000 chemically diverse small molecules.
A custom set of 20,000 compounds which have been selected for low cellular toxicity and excellent coverage of the chemical space. This diverse library is the DiverSet E from Chembridge – it’s a well-established 30k compound set which contains a lot of interesting structures and has generated many interesting hits in our hands. This set contains a vast structural diversity which has been selected from over 500,000 compounds.
Three smart sets of 20,000, 40,000 and 50,000 compounds each with excellent coverage of the chemical space selected from a set of over 850,000 compounds. Our diverse smart libraries were selected from large compounds sets of 600k and 250k compounds. Using large computer clusters with GPU processors (250 nodes and more) at the CNSI, we filtered the sets for compounds which were drug like and did not have any other liabilities, fewer than 8 rotatable bond etc. and then broke the compounds into clusters of similar structures. This was a challenging process which took about 3 weeks computing time on the cluster. We then sampled these clusters for diversity and included the resulting compounds into our libraries. The resulting compound libraries have excellent properties (at least rule of 5 or better) and they are proprietary to the MSSR.
UCLA In-House Collection
Various professors have donated their compounds to our in-house collection and so far we have collected about 5000 compounds. These libraries are extremely diverse and range from natural products to compounds which have been synthesized using diversity-oriented synthesis.
Other Functional Genomics Libraries
Arrayed siRNA Libraries
A human and mouse druggable genome wide collection is available for screening. The two libraries cover about 7,000 genes each. We have four siRNA’s per target, which are screened in a non-pooled format. Kinases and GPCR’s are available as sub-libraries.
Arrayed shRNA Library
Our arrayed shRNA libraries contain over 60,000 clones targeting about 18,000 genes with an emphasis in coverage on desirable target classes such as kinases, proteases, phosphatases, GPCRs and ion channels. In addition to the traditional target classes we offer various custom libraries such as a validated cancer specific shRNA set of about 150 targets from the NCI and a cancer specific set of over 2000 clones covering 500 cancer related genes selected by the Sanger Institute. Other sublibraries cover transcription factors, ubiquitinization and de-ubiquitinization pathways, apoptosis etc. These libraries are proprietary to the MSSR as they were custom selected and arrayed at the MSSR. The capability of customizing shRNA libraries enables the MSSR as well to tailor shRNA libraries to the needs of a particular Principle Investigator’s laboratory.
Arrayed cDNA Library
A human and mouse mixed genome wide collection is available for screening. The libraries covers about 16,000 genes and is a consolidated version of the expressible clones from the MGC collection of full length cDNA clones. These clones are in the pSPORT6 expression vector which uses the CMV promoter to drive the expression of the insert. We can as well customize libraries to your requirements as needed. We also offer a 13,000 clones strong lentiviral cDNA library in a pLX304 vector with V5 tag on the c-terminus and also blasticidin resistance for selection.
Yeast Knockout Collection
A genome wide set of non-essential knockout mutants of yeast is available for screening in both mating types (alpha and A). The strain collections have been condensed into 384 well plates to facilitate high throughput screening. We have successfully used this library as well for synthetic genetic array screens.
E.coli Knockout Collection
A genome wide set of non-essential knockout mutants of E-Coli is available for screening. The strain collections have been condensed into 384 well plates to facilitate high throughput
E.coli Promoter Collection
A set of about about 2000 E-Coli promoters with GFP as reporter gene is available for screening. The strain collections have been condensed into 384 well plates to facilitate high throughput screening.